
We (Basically) Stopped Writing Prompts.
Here's what we do instead.
Six months ago, we were doing what everyone does: writing prompts by hand. Different languages, different models, endless A/B tests. It didn't scale.
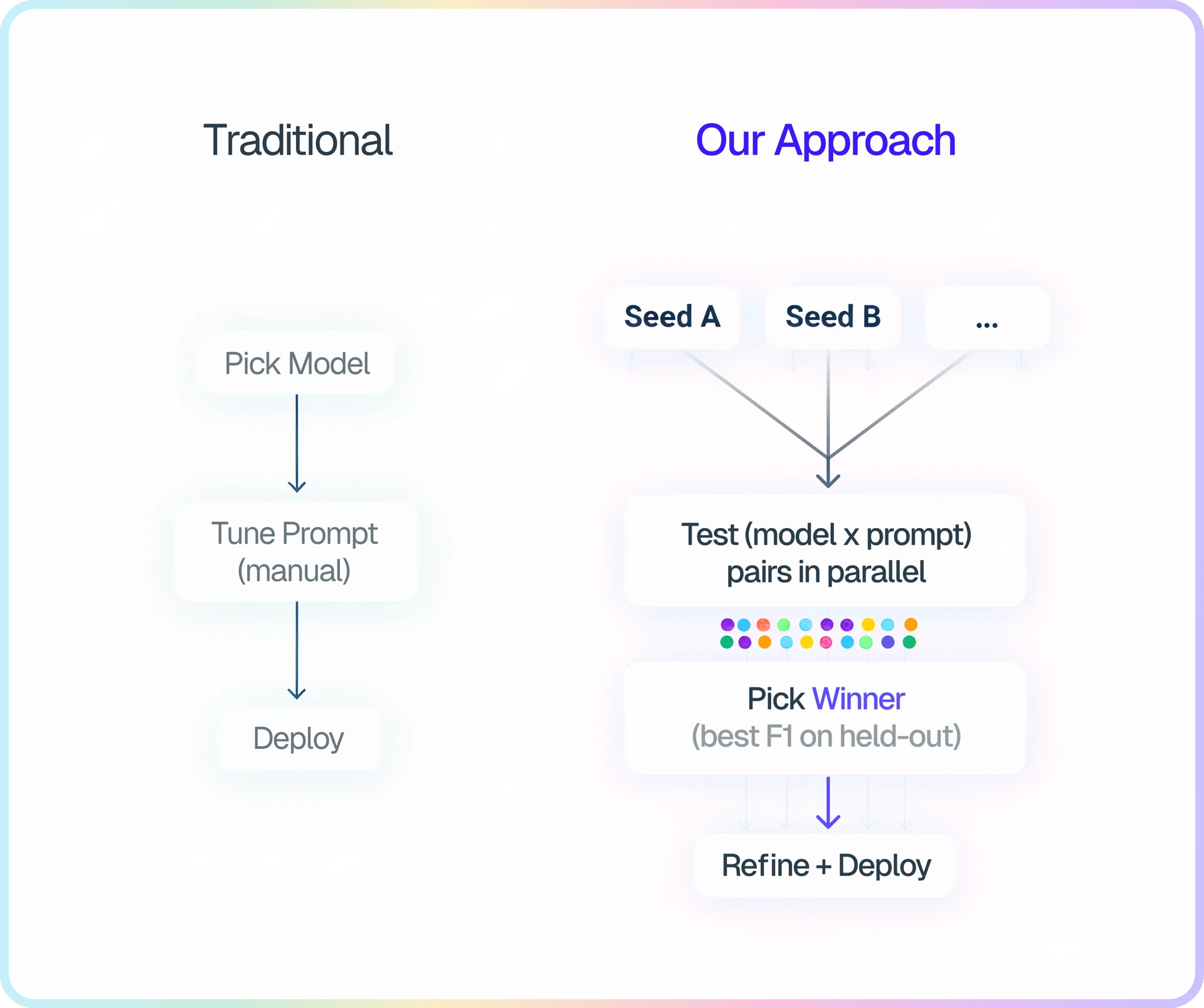
Now, for our code review, we've mostly stopped writing prompts. An LLM does it for us. We define the task, throw in a few competing strategic directions ("think like an attacker," "trace every code path"), and our 'auto-tune' system tests them all, picks the winner, and optimizes from there.
Automated prompt optimization isn't new. DSPy, TextGrad, and others have explored this space. What surprised us were the strategies that emerged. Auto-tune discovered approaches we wouldn't have tried—like using different models for different subtasks, or pairing aggressive detection with ruthless validation. It would have taken a lot of trial and error for us to come up with these combinations.
It also surfaced something fundamental: different models have different intuitions about what counts as a bug, how severe it is, and when to speak up. These aren't flaws; they're just different calibrations. Auto-tune learned to harness those differences: use an aggressive model for detection, a precise one for validation, and filter where a model's confidence runs hot.
The problem
We do AI code review. It needs to work across every language developers use—and they use a lot. Each language has different idioms: Go's explicit error handling, Python's duck typing, TypeScript's type coercion. A prompt that catches real bugs in Go flags noise in Python. That's a lot of combinations to tune by hand.
The feedback loop was brutal. Hours to get results on a single change. A constant stream of new foundational models to try. We couldn't build intuition about a given model fast enough to keep up, and when a new combination of individual improvements led to regressions, we usually couldn't explain why.
What didn't work
A/B testing was too slow. Each benchmark run took hours. We'd tweak a prompt, run it against our benchmark of 500+ known bugs, wait for results, tweak again—an endless cycle. And model updates could invalidate our learnings before we had a chance to leverage them.
The deeper problem was scale. Testing prompts across multiple models, multiple languages, multiple strategies; building intuition across an ever changing landscape was nearly impossible. We only ever experimented with a few models because that's what was feasible. We were searching a subset of the space.
Few-shot examples backfired. We added examples of specific types of bugs to look out for in the prompt. It worked for the specific cases that we were targeting but it also didn't scale. When we added a Python example, Python improved but TypeScript got worse. In some cases, removing the examples entirely improved results. The few-shot examples were hurting more than helping.
What worked
Last year we found a paper called Agentic Context Engineering (ACE) that treats prompts as evolving playbooks, refined based on what's working, using an LLM to analyze failures and propose improvements.
We built on their approach and shipped it to production within a few months. Our key extension: we jointly optimize both models and prompts. ACE optimizes prompts for a fixed model. We test multiple (model × prompt × model parameter) combinations in parallel and hill climb efficiently. (And yes—the system that writes prompts is itself prompted. We did have to write that one by hand.)
How this differs from DSPy: DSPy optimizes prompts for a fixed model. We search over (model × prompt) combinations jointly, so auto-tune can discover that GPT-5.2 needs a different approach than Opus. This isn't fine-tuning or hyperparameter search—it's prompt optimization (complementary to fine-tuning). It's closer to having a dedicated prompt engineer iterate on prompts, except auto-tune can test ideas in parallel and doesn't get tired.
Those strategic directions are seeds, not finished prompts. One might say "trace every code path systematically." Another might say "think like an adversary trying to break the code." Auto-tune tests each seed across multiple models, picks the winning combination, and refines it—discovering patterns we'd never have found ourselves.
The approach is agnostic to how you're using the prompts: whether your prompts drive simple API calls or complex agentic workflows (we use both), they all benefit from systematic optimization.
Auto-tune runs candidates in parallel, scores them on a held-out test set, and refines the winner. We borrowed existing ML techniques:
- Severity-weighted scoring. We don't optimize raw F1. Each bug severity tier is worth 5× the next, so critical bugs score 125× higher than low-severity ones (5³). False positives are penalized. The scoring function focuses our optimization on what matters.
- Learning rate controls edit magnitude. Borrowed from ML: at low learning rates, the curator can only tweak wording. At high rates, it can rewrite entire sections. We decay on success, boost when stuck, just like adaptive optimizers.
- Anti-overfitting guidance. The prompt curator (an LLM that analyzes failures and proposes improvements) is instructed to avoid making changes to address a specific result and instead identify the underlying pattern across a batch.
What we discovered
Each model has its own calibration: what it considers a bug, how severe, when to report. These differences show up even with zero-shot prompts; the models just disagree out of the box. Auto-tune learned to harness those differences rather than fight them.
Here are a few patterns it found:
GPT-5.2 hedges
GPT-5.2 hedges when it's uncertain. It says "this could potentially cause an issue" instead of committing. We found that hedging correlates strongly with false positives: the model is expressing uncertainty, and that uncertainty is a signal. Auto-tune learned to detect this: modal language like "could," "potentially," and "may" became a filter. If the model hedges, the output gets rejected.
Gemini 3 rambles
Gemini 3 sometimes thinks out loud. "Wait, let me re-read that." "However, on second thought..." When it does this, it's usually about to get the answer wrong. The rambling is a tell. Auto-tune learned to catch this—words like "wait," "however," and "re-reading" became rejection signals. Not all models do this. Opus, for instance, doesn't ramble—so it doesn't need this filter.
Separating detection from validation
One pattern auto-tune discovered: pair a permissive detection with strict validation. For detection: "Prefer reporting MORE issues over fewer. False positives are acceptable; do not self-censor." This sounds wrong because we'd always tried to minimize false positives everywhere.
But it works if validation compensates: strict rejection of hedging, speculation, and anything that can't be proven from the code. One optimizes for recall; the other optimizes for precision. Neither would work well in isolation.
The calibration differences make this necessary. Given the same "maximize recall" directive, Opus flags 199 potential issues. GPT-5.2 flags 3,923. Same task, 20× different output. (GPT-5.2 would absolutely build the paperclip factory.) Without strict validation, that aggressive detection is unusable.
We probably wouldn't have tried pairing different models for different subtasks without auto-tune—it seemed unnecessarily complex. But different models have different strengths: Gemini 3 is aggressive at finding edge cases but noisy; GPT-5.2 is better at following instructions; Opus is more precise out of the box but also more conservative.
These specific patterns will change as models evolve, that's the point. Auto-tuning can be re-run when we upgrade models, and find new patterns each time. The insight isn't any single filter; it's that systematic search finds what works faster and more scalably than manual tuning.
Results
Auto-tuning now catches ~3.5× more high-severity bugs with ~50% fewer false positives on TypeScript. On Python, it generates ~65% fewer nitpicks and ~45% fewer false positives. On Java, ~50% fewer incorrect or low-value comments. These results are on held-out test data. We re-split the dataset each epoch to avoid overfitting to a single test set.
Scope and limitations
It's expensive to run. Each full optimization burns thousands of LLM calls across model/prompt combinations. We run it when we add a new language or upgrade models—not continuously.
This requires labeled data. You need examples to score against. We had 500+ labeled bugs; without that benchmark, you can't run this system. If you're starting from scratch, building the dataset is the real work.
We've only validated this on code review. The underlying principle—that models have different calibrations you can learn to harness—likely applies elsewhere, but we haven't tested it on other domains. If you've experimented with automated prompt optimization or (model × prompt) search, we'd be curious to hear what you've found. Feel free to reach out.